
))
Benchmarks 201: Why Leaderboards > Arenas >> LLM-as-Judge
Manage episode 428597745 series 3451473
Content provided by swyx & Alessio. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by swyx & Alessio or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://player.fm/legal.
The first AI Engineer World’s Fair talks from OpenAI and Cognition are up!
In our Benchmarks 101 episode back in April 2023 we covered the history of AI benchmarks, their shortcomings, and our hopes for better ones.
Fast forward 1.5 years, the pace of model development has far exceeded the speed at which benchmarks are updated. Frontier labs are still using MMLU and HumanEval for model marketing, even though most models are reaching their natural plateau at a ~90% success rate (any higher and they’re probably just memorizing/overfitting).

From Benchmarks to Leaderboards
Outside of being stale, lab-reported benchmarks also suffer from non-reproducibility. The models served through the API also change over time, so at different points in time it might return different scores.
Today’s guest, Clémentine Fourrier, is the lead maintainer of HuggingFace’s OpenLLM Leaderboard. Their goal is standardizing how models are evaluated by curating a set of high quality benchmarks, and then publishing the results in a reproducible way with tools like EleutherAI’s Harness.
The leaderboard was first launched summer 2023 and quickly became the de facto standard for open source LLM performance. To give you a sense for the scale:
Over 2 million unique visitors
300,000 active community members
Over 7,500 models evaluated
Last week they announced the second version of the leaderboard. Why? Because models were getting too good!
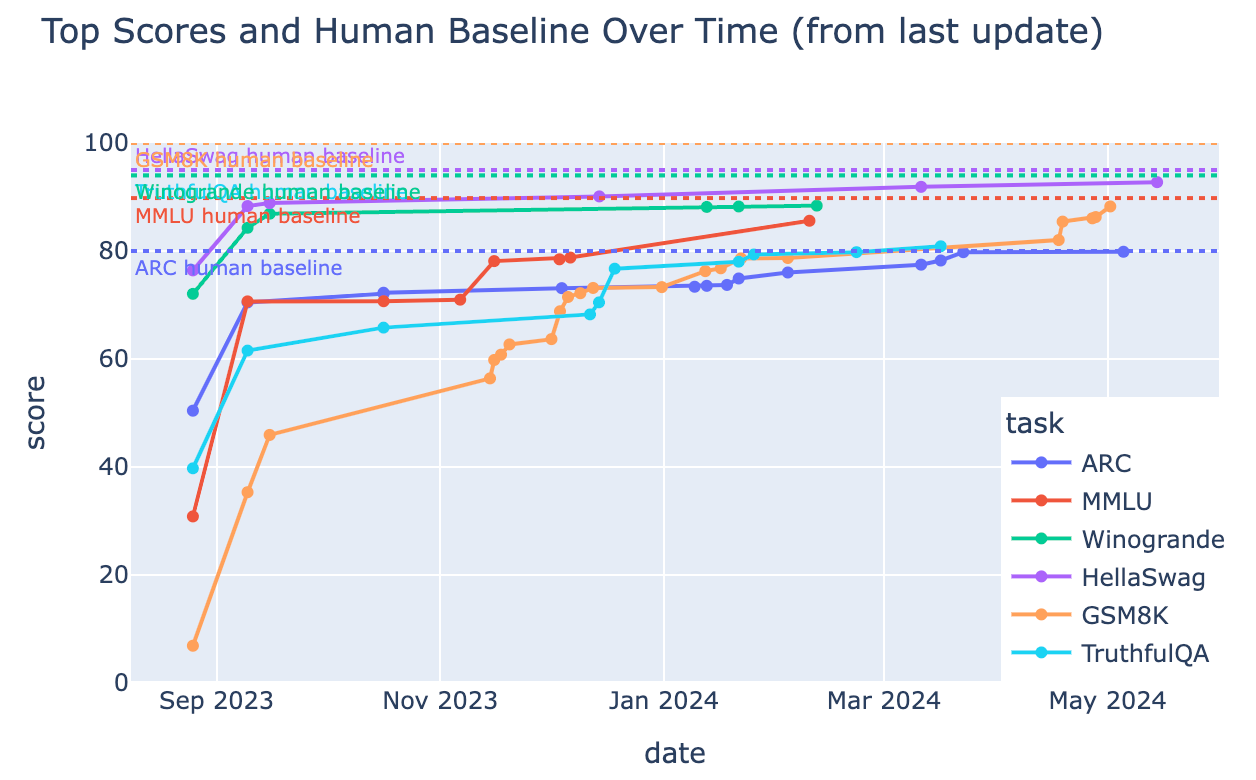
The new version of the leaderboard is based on 6 benchmarks:
📚 MMLU-Pro (Massive Multitask Language Understanding - Pro version, paper)
📚 GPQA (Google-Proof Q&A Benchmark, paper)
💭MuSR (Multistep Soft Reasoning, paper)
🧮 MATH (Mathematics Aptitude Test of Heuristics, Level 5 subset, paper)
🤝 IFEval (Instruction Following Evaluation, paper)
🧮 🤝 BBH (Big Bench Hard, paper)
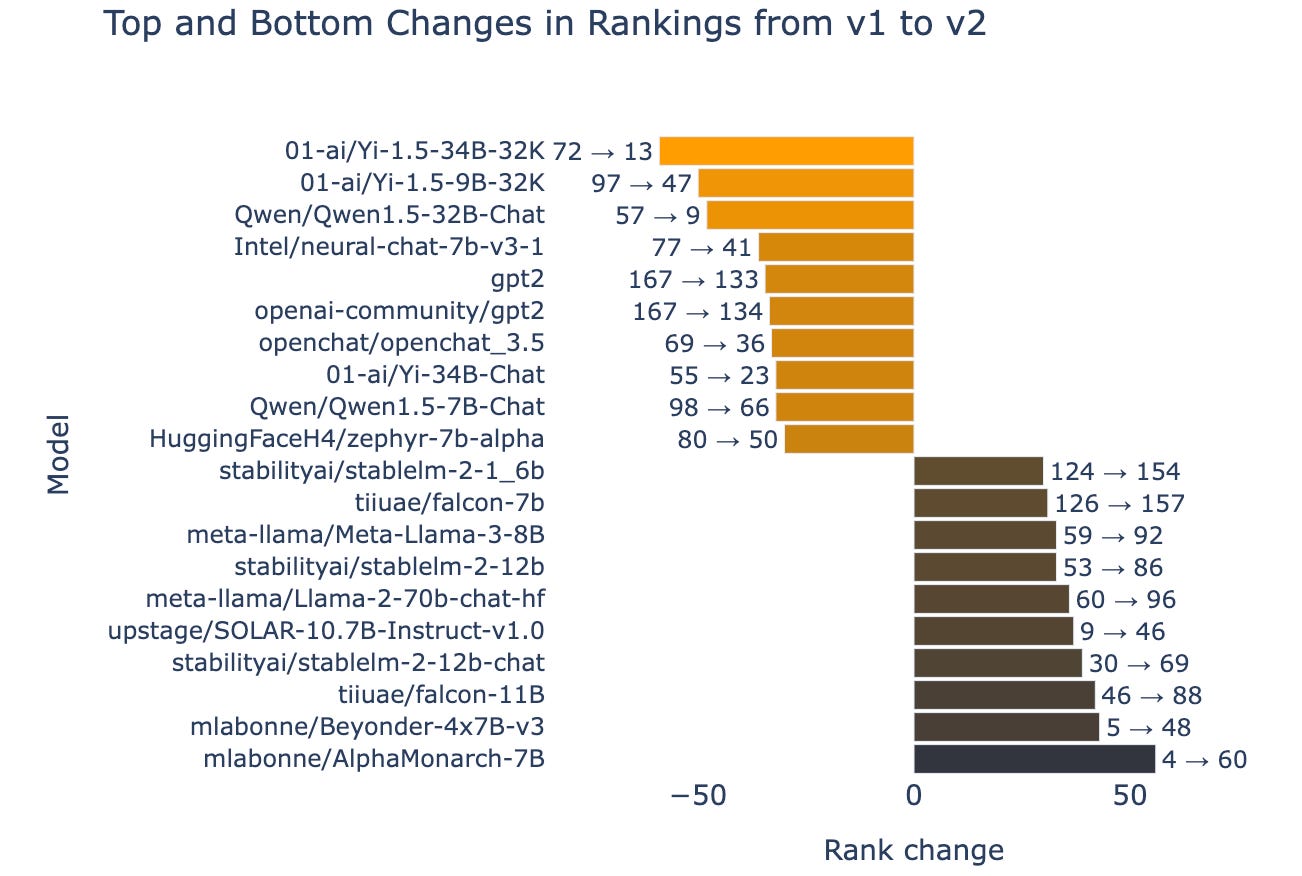
You can read the reasoning behind each of them on their announcement blog post. These updates had some clear winners and losers, with models jumping up or down up to 50 spots at once; the most likely reason for this is that the models were overfit to the benchmarks, or had some contamination in their training dataset.
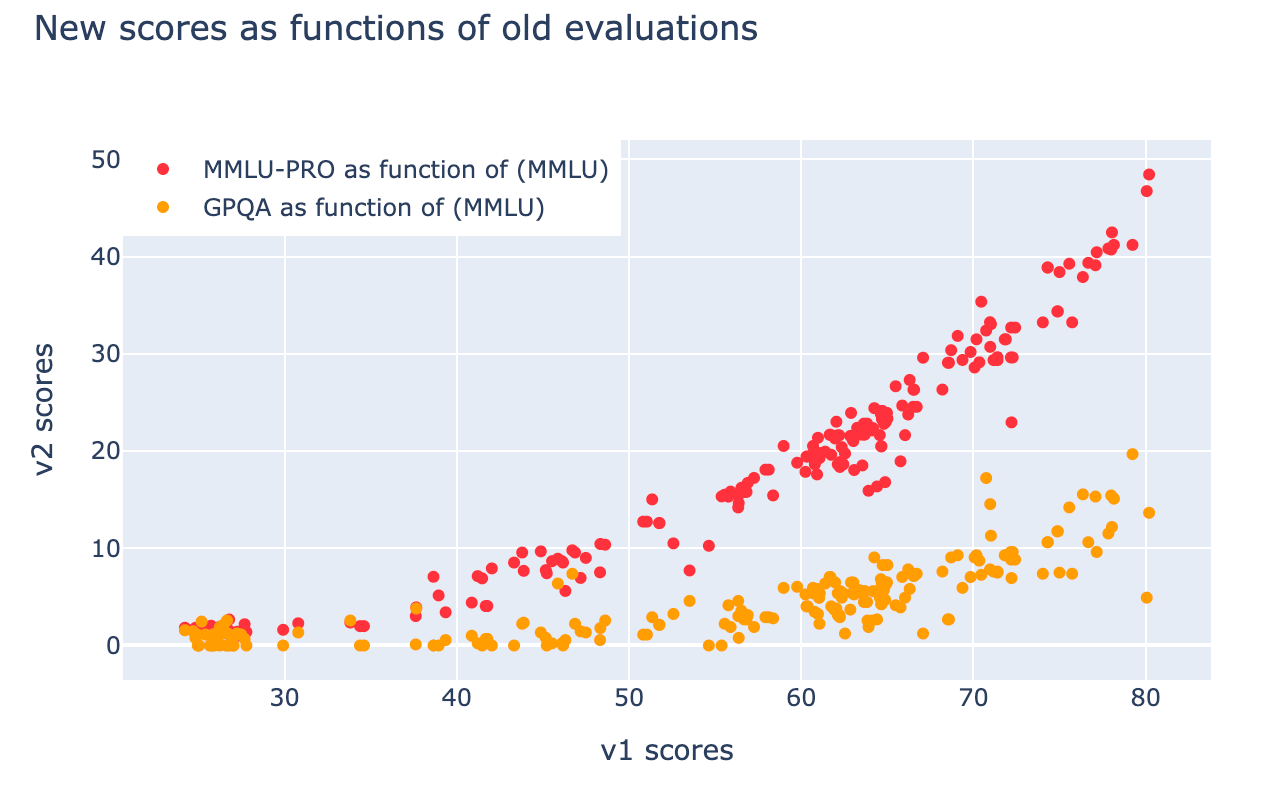
But the most important change is in the absolute scores. All models score much lower on v2 than they do on v1, which now creates a lot more room for models to show improved performance.
On Arenas
Another high-signal platform for AI Engineers is the LMSys Arena, which asks users to rank the output of two different models on the same prompt, and then give them an ELO score based on the outcomes.
Clémentine called arenas “sociological experiments”: it tells you a lot about the users preference, but not always much about the model capabilities. She pointed to Anthropic’s sycophancy paper as early research in this space:
We find that when a response matches a user’s views, it is more likely to be preferred. Moreover, both humans and preference models (PMs) prefer convincingly-written sycophantic responses over correct ones a non-negligible fraction of the time.
The other issue is that Arena rankings aren’t reproducible, as you don’t know who ranked what and what exactly the outcome was at the time of ranking. They are still quite helpful as tools, but they aren’t a rigorous way to rank capabilities of the models.
Her advice for both arena and leaderboard is to use these tools as ranges; find 3-4 models that fit your needs (speed, cost, capabilities, etc) and then do vibe checks to figure out which one is best for your specific task.
LLMs aren’t good judges
In the last ~6 months, there has been an increased interest in using LLMs as Judges: rather than asking a person to evaluate the outcome of a model, you can ask a more powerful LLM to score it. We covered this a bit in our Brightwave episode last month as well. HuggingFace also has a cookbook on it, but Clémentine was actually not a fan of this approach:
Mode collapse: if you are asking a model to choose which output is better, it will just self-reinforce its own preferences. It will also prefer models from its own family (i.e. GPT models will prefer other GPT models over Claude outputs). If these outputs are then used to fine-tune the model, you will further mode collapse the model. Cohere for example has said they do not train on any model-generated data to avoid this.
Positional bias: LLMs usually prefer the first answer, so you can’t naively give them options and ask them to rank them, but you also have to mix up the order in which they appear.
Don’t score, rank: rather than asking a model to assign a score to each output, you should have it stack-rank them. The models aren’t trained to score things, so even though they might understand what response is better, assigning a score to it is hard.
If you do have to use LLMs as Judges (we aren’t all ScaleAI-rich!), she suggested using an open LLM like Prometheus or JudgeLM to make sure you can reproduce those rankings in the future.
Full Video Podcasts
Show Notes
Companies and Organizations
ICLR (International Conference on Learning Representations)
People
Projects, Models, and Benchmarks
Timestamps
[00:00:00] Introductions
[00:02:32] How Clémentine went from geology to AI
[00:05:52] Origin of the OpenLLM Leaderboard
[00:09:06] How v1 Benchmarks Were Selected
[00:10:49] The Problem with Current Benchmarks
[00:13:45] Saturating benchmarks and the future of evaluation
[00:16:14] Issues with human evaluations
[00:24:07] AI girlfriends as the multi-turn benchmark
[00:25:35] What's New in OpenLLM leaderboard V2
[00:28:12] Benchmark Answers Black Market
[00:30:21] The impact of prompt formatting on model evaluation scores
[00:33:30] Difficulty and Computational Constraints of Evals
[00:36:28] The Responsibility of Setting Standards
[00:40:35] The Economics of OpenLLM
[00:44:15] Long context reasoning benchmarks
[00:46:34] Agent benchmarks, GAIA, and the ARC AGI challenge
[00:50:43] Vibe check for benchmarks
[00:53:16] Request for benchmarks
[00:56:48] v3 predictions?
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.
Swyx [00:00:13]: Hey, and today we have a super special guest that we've been trying to book on the schedule for a while. It's Clémentine Fourrier. I'm trying my best to do the French, but maybe you can do a better job of it than me.
Clémentine [00:00:26]: This was perfect. It's Clémentine Fourrier, but your pronunciation was really on point.
Swyx [00:00:31]: There was a Fourrier, which is very sort of French intonation, which I don't really understand. So I'll introduce you off of your LinkedIn and I would love for you to fill in the blanks. You are currently a research scientist at Hugging Face and the maintainer of the OpenLLM leaderboard, which we'll talk about very shortly. Previously, you were at INRIA as well, but then it looks like you also concurrently got your PhD at the same time. How does that work? Is that a very common thing?
Clémentine [00:01:01]: So I basically did my PhD at INRIA, technically. So INRIA funded my PhD and PhDs in France are three years, but I also worked as an engineer at INRIA before my PhD, hence maybe the confusion.
Swyx [00:01:14]: I think there's a rise in universities having sort of industrial attachments to these things. And I think it actually makes for a much more grounded study, especially if you're doing your sort of graduate studies and all these things. I think it's rising in North America as well with Berkeley and with Waterloo in Toronto. Cool. Like, you know, there's, there's a lot of other things we can, we can introduce. I can't really pronounce the name of the, the university you went to, but what else should people know?
Clémentine [00:01:44]: So I actually, technically I'm an engineer in geology. So I studied rocks and I graduated in 2015 after having done like extensive studies about rocks. And I discovered I was very bad at it, but I was very good at computer science. So I went to computer science. What stuck with me though is that geology is very much an experimental science. And I think that machine learning is very much an experimental science too, even though people want to claim that it's pure math. And I worked on several machine learning projects throughout the years, a bit of the prediction of illnesses in the brain at Brain and Spine Institute in Paris. I worked as an engineer in a research team in NLP where I did my thesis and then I joined Hugging Face.
Swyx [00:02:32]: Do you have a favorite rock fact or sort of rock story before we get into the NLP stuff?
Clémentine [00:02:38]: Okay. I was not expecting this question.
Swyx [00:02:43]: I did my geography A-levels and I always loved learning about like isostasy and stuff like that where you have different plates kind of up and down in the mantle. And I don't think people think about vertical dimensions to geographical plates, but it's real.
Clémentine [00:03:02]: Yeah, definitely. And like when you do geology, the time scale is just not the same. There is like one specific place in France where you can see rocks that are 1 billion years old and like the sheer scale of this is huge. Yeah, that's what I loved about geology, that the scale is completely different and it makes us see the rest of the world in perspective, I guess. We are like a blink in the length of time of the earth.
Swyx [00:03:31]: But a very significant blink. So you went from large monoliths to large language models. I don't know how to make that transition there. And yeah, so like maybe could you describe your journey into Hugging Face? Obviously, I think you're like our second or third person from Hugging Face on the podcast and it's like the definitional sort of open AI company, maybe the real open AI.
Clémentine [00:03:56]: Yeah, I did. So at the end of my PhD, I realized that I did not want to stay in academia. And I actually got contacted by Meta because they wanted to offer me an internship. And I was like, wow, I can do an internship during my PhD. Where do I want to do an internship? And so I applied to Hugging Face. Thank you Meta for like opening this door for me. And I actually was hired to work on pre-trained graph transformers. And we train foundational graph transformer models. And it was a very interesting project. But it was a bit hard to accomplish with the resources we had at the time. We tried it for three months, gave it three months more. So the first three months were my internship, three months more were my first three months at Hugging Face. And then we dropped it. We still left a lot of artifacts about graph machine learning that people can use. But we stopped trying to basically compete with Google on this specific topic. And then we had a team which was doing model, like literally LLM training at the time. And we made a list of the different topics. And one topic which people were not interested in was actually evaluation. So I spent a month just reading all the papers I could about evaluation. And I discovered that it was very interesting. And so we started setting up our own internal evaluation suite, which later became LightEval. And once Tom saw that we were interested in evaluation, he sent us the leaderboard, which was a completely different initiative at the time. And then we basically became a small team doing evaluation and leaderboards at Hugging Face. I'm saying we because I'm including Nathan Habib, who is the engineer working with me on evaluation and leaderboards at Hugging Face.
Alessio [00:05:52]: Just to set the stage, maybe back in April 2023, we did our Benchmarks 101 episode. And I think everybody was trying to figure out how do you actually evaluate these models. And the models were not very good. Well, first of all, there were not that many models. And the models were not very good at a lot of things back then. Can you maybe give people a bit of a background on how many models you're testing on the leaderboard? I know it's thousands and thousands of models now. And then how you're thinking about what benchmarks matter. And we can go into some of the details. But I think just explain the scale, how many models there are, how many people contribute to this community outside of the actual Hugging Face maintaining team. Okay.
Clémentine [00:06:33]: So very beginning, it was really just an internal research project, because our reinforcement learning team wanted to compare some results that they had with published papers, and they did not manage to. And so they opened a small leaderboard where they had manually evaluated a bunch of models. And the community really took over. People were super motivated. And after one month and a half, that's when it was given over to Nathan and I, so that we could make it into an actual engineering product, which could run an actual production rather than a research project. So at the moment, we have evaluated on the version one of the OpenLLM leaderboard, 7,400 models, which have been community submitted for most of them. I think around 800 discussion threads of users interacting with us, either for support or for suggestions. We have had several million visitors since the creation of the leaderboard. And yeah, the scale of it is quite huge. We actually have, from time to time, startups sending us thank you messages saying, oh, our model ranked so high on the leaderboard that we actually got a funding round thanks to you. And so they are very happy about this, and we get thank you messages. So it's quite used, especially by the community. A lot of the community is using it to test their methods and test how well their ideas perform against the SOTA models.
Swyx [00:08:11]: It's instructive to rewind back maybe one, maybe two years ago when this kind of leaderboard practice wasn't normal. It's not normal to have an independently validated leaderboard. Everyone just kind of runs their own evals and publishes their evals against their models on their own paper, and it's not reproducible. So I think it's really about reproducible science. I think the only other, before this, it was kind of like ML perf, that's the other big leaderboard that I can think about where, obviously, maybe AlexNet, specific competitions, specific benchmarks, but not something that aggregates across all the other benchmarks. Maybe HuggingFace was involved in BigBench in the earlier days.
Clémentine [00:09:03]: Maybe some of the other people in the team.
Swyx [00:09:06]: Anyway, so this is the first time getting everything together. And so what was your thinking around inclusion, right? Because I think that's another element that we'll talk about V2 later on, but V1 was your selection of here are the top benchmarks. I don't know if there was any story to tell behind that apart from, was it obvious? Were there any controversial choices?
Clémentine [00:09:29]: So for V1, Edward Beeching and Lewis Tunstall, who were our reinforcement learning team at the time, basically wanted to look at the scores which were there in every paper. So they took all the big RL papers of the time and they looked, and you had GSM 8K, you had MMLU, you had ArcChallenge, systematically. So they took those benchmarks because, yeah, they were kind of obvious which ones were the standards of the time. And when we added evaluation, I think we actually added GSM 8K later on. We also tried to add Drop, which we dropped because there was an implementation problem. When we did our round two, we based ourselves, like not the V2, but I'm going to say V1.5. We interacted a lot with the community to see what was missing in terms of evaluations, what were the capabilities that people wanted to see. And we added those datasets at the time. We keep interacting a lot with the RLHF team, like Lewis Tunstall specifically has been very helpful in helping us choose the last set of evaluations for the V2 also.
Alessio [00:10:49]: In the V2 announcement blog posts, you mentioned some of the issues that all their benchmarks had. I feel like it's funny to me that now everybody's bringing up these issues, but before they were just using the numbers for marketing and promotion saying, look how good we do. But now it's like, no, actually the benchmark is wrong, like it should be harder. Are people just finding out recently about these problems because now the scores are getting so high that you're actually inspecting the benchmarks and maybe in the past you were scoring so badly that maybe you weren't as worried about the overall quality? Or what do you think now, like, you know, the last maybe like two, three months have been really like where the leaderboard and like has been kind of like taken off as far as popularity and then why it's now the right time to do V2. And then we'll talk about what V2 actually is.
Clémentine [00:11:36]: For the first question, when you read evaluation papers, actually a lot of the datasets from, I'm going to say it's a pre-LLM period, are datasets which have been turked basically. So datasets which were made by people which are underpaid, where English is usually not the native language. And so a lot of them have a lot of mistakes and it's kind of obvious just from reading the paper that there are going to be issues because when you generate 10,000 samples, it's quite hard to manually verify each and every one of them. The datasets we've been using, such as MMLU, ArcChallenge and stuff, were of higher quality from the start, but the attention which was given to them forced people to at one point really explore the datasets to see where the scores were coming from. And yes, at the moment, like when a benchmark reaches saturation, so when models basically get the same performance as humans on a benchmark or go above human performance, which the press really likes to say, what it actually says is usually that the models are completely contaminated on said benchmarks and they are now doing errors which humans would not be doing. For example, for MMLU, human performance is at 80-something, also because a number of the questions that humans fail are actually wrong. So the correct answer to those questions is actually a wrong answer. And so the humans who got a wrong answer on this actually had the correct answer. And so if you're getting above humans on this, you have actually learned to predict very wrong stuff, which I find absolutely fascinating. So evaluation has good enough signal-to-noise ratio, if the quality is high enough, it's going to be useful enough for a period of time, and once you reach saturation, you want to inspect it more.
Swyx [00:13:45]: There's a three-way race condition as we all figure out who's going to go first. Yeah, so I really like this concept of evaluation. So actually, yeah, I think there's typically what I always say is like sort of 25 is random chance, 50 is average human, 75 is expert human, 90 is you're cheating. And the question now is that most models are high 80s in MMLU, and so it's not challenging anymore or we've sort of saturated it. It looks like some people have put out MMLU Pro. I've seen a few variations of what comes after MMLU. Dan Hendrycks, who came out with MMLU, has promised to make his own MMLU. To me, what I worry about MMLU Pro or any other MMLU variant is that this will last one year. Yeah.
Clémentine [00:14:39]: And then what? And then we do Leaderboard v3. Oh, okay. That's it?
Swyx [00:14:45]: I mean, yes.
Clémentine [00:14:46]: Sorry to disappoint, but like, we basically expect the scale of AI progress to go so fast that anyway, we will have to renew them. Of course, some of it will be for contamination issues, people trying to game the leaderboard, cheating and stuff. But a lot of it will just be because the benchmarks will have become just too easy, like the scale of the progress we did in just one year on those benchmarks is already huge. And I think that's also why the leaderboard was so important, because everybody wanted to climb the scores. And so those evaluations really saw a jump in the performance, like we've got curves on version one, which is archived, but still accessible, of model performance through time. And you can really see the steps which you had for each evaluation.
Alessio [00:15:47]: I think the other thing to talk about here is whether or not humans are good at judging and evaluating these models. We're kind of slacking about it over today, but I would love to get your thoughts. It's like, at what point are we not the best people to test these models anymore? And how do you kind of balance the machine benchmarks, the MMLUs of the world, the LMSIS kind of human-driven rating, and then the AI judges, so to speak?
Clémentine [00:16:14]: I have many opinions about human evaluation. But I think that...
Alessio [00:16:20]: We've got time, so...
Clémentine [00:16:23]: Basically, to go back to the initial separation, just to make it clear, so automated benchmarks, like the one we're using on the OpenLLM leaderboard, are usually fair and reproducible. Every model gets evaluated in exactly the same way, and you can really reproduce the scores you get. They tend to be also limited in the scope of what they allow to evaluate, because if you're looking at a multi-choice question, well, it's not telling you how good the model is at generating poetry, for example. So people have been using human evaluations to kind of go further in terms of the capabilities we can evaluate. We've got three types of human evaluations, in my opinion. We've got vibe-check evaluations. We've got Arena-type evaluations, like the LMsys Chatbot Arena. And then you've got human experts, so paid human annotators who will evaluate stuff, which is the approach that Scale has, for example. I think that paid human experts is a really good way to evaluate models, because you can actually give a proper grid of things you want people to check. And because they are actually paid to do so, you can hope for quite a high quality. But since human experts are expensive, people have tried to use model-as-judges, which is our third approach. Model-as-judges, I won't delve too much into this at the moment, but I think they are a problem for the field, actually. I think people should stop using LLMS judges, because they have a lot of subtle biases that they introduce in evaluation. They tend to prefer outputs from the same families. They tend to prefer first answers, which is called a position bias. They tend to prefer long and verbose answers. They struggle with evaluating models in a continuous range. So if you absolutely want to use a model-as-a-judge for your specific use case, do not use GPT-4 also because it's closed source and it will not be reproducible at all. Use a small model such as Prometheus or JudgeLM, and just use it to give you rankings, such as this option is better than this other option. Don't ask it to give you scores, because at the moment those models are not able to do this in a proper fashion. And I saw on Twitter a couple of days ago, Aidan from Cohere, who was saying that their models have a very distinct style, because they don't train with other models' outputs. They actually took the time to gather super high quality data. And other models kind of sound the same because of this. And I think for evaluation, it's going to be the exact same problem. If you choose your model based on model evaluation, you're going to make it kind of the same as all the other models. To go back on human evaluation, if we go on this distinction of VibeCheck versus R&R versus human experts, I think that VibeChecks are actually quite necessary. If you are an engineer and you want to know which model is best for your specific use case, please do a VibeCheck. You can look at a general leaderboard, like the OpenLLM leaderboard. It will tell you which model is best in a range of tasks. And for your use case, you need to test it yourself. For the R&R or R&R-like systems in general, they are trying to rely on wisdom of the crowd approaches. But the wisdom of the crowd tends to work for quantifiable things, right? So it was initially done to try to see if a crowd could average the weight of a pig at a farmer's market in the 18th or 19th century. And it's been reproduced by asking people to estimate a number of a marble in a jar. And for anything which is like super quantifiable, it works very well. But when you're just telling people what is a good output, it's much harder to get something reproducible and experimental science is based on reproducibility, like rigorous protocols. And when using an R&R, you're not getting that. I think that an R&R is a very good sociological experiment, however. I think it's telling you a lot about the users. It's telling you a lot about what are the prompts, how people interact with models. And I also think that you can crowdsource evaluations if you have clear metrics. For example, for red teaming. You can definitely crowdsource red teaming because whether the model gave you private information or whether the model was toxic is something you can have a strict like yes or no answer, in a sense. But for anything else, it's very limited. There were a bunch of papers which were very interesting about this at ICLR this year. There was the psychophancy paper of Anthropic, where basically they showed that humans tend to prefer models which go their way and which agree with them because we want people to like us and apparently we want models to like us too and to agree with us too.
Swyx [00:21:49]: Arguably, that's alignment, you know, we want models to like humans. Sometimes it's good.
Clémentine [00:21:56]: Yeah. But you also want humans to actually say the truth. Disagree. Yes. Exactly. To challenge you. Definitely. If what you're thinking is not factual. There was also this cool paper by Cohere and the University of Edinburgh, which was human feedback is not gold standard, I think. And where they actually established super interesting things such as humans prefer models which are over assertive. And if you have the choice between an answer which is false, but given super assertively and an answer which is right, but not as assertive, humans naturally will say the assertive but false answer is a better one. So basically, Arenas are not giving you factuality, which should be a super important aspect of LLMs, I think.
Alessio [00:22:52]: That's the same with everyday life. You know, people just trust the person saying the thing assertively, even though it's false, and then actually try and figure out what the truth is. So yeah, I think you mentioned that, you know, it's like a more social experiment. I think it's a good point. Like the same biases that people have interacting with humans, they kind of put in the models themselves.
Clémentine [00:23:15]: Yeah, definitely. In these things. But there's also the fact that some like the judgments and the likings that we have in real life do not necessarily have the same impacts as LLMs, which are used in production, right? So you don't want the best LLM, according to everybody, to be the one which is going to be the most psychophantic and then get propaganda chatbots or something. On anything like an Arenas, there can be also the problem of the lack of diversity of the annotators, because most of the users of the chatbot arenas, for example, tend to be, from what I gathered, men from the US. I'm sorry, but this is not a diverse demographic. So those are reasons for which human evaluations, in my opinion, are quite limited.
Swyx [00:24:07]: I'll throw in one more, which is, I think the sample of the chatbot arena data is actually out there. And most of them are single turn tests as well.
Clémentine [00:24:19]: Definitely.
Swyx [00:24:20]: So multi-turn is not tested at all.
Clémentine [00:24:22]: At the same time, I won't complain too much about this because we also tend to not evaluate multi-turn for automatic benchmark. So I cannot really say anything about this.
Swyx [00:24:32]: The AI girlfriend community has got you there. They're very good at the multi-turn and you just need to go to OpenRouter to see which the top trending bots are. For those who don't know, a lot of this is covered in your blog posts, which I think you wrote after ICLR, which is, let's talk about LLM evaluation. You cover sort of a top-down, what you think about evals, and you even point to RavenWolf for the vibe check, who apparently blogs a lot on HuggingFace, because HuggingFace is now a blogging platform and does really good vibe checks, apparently.
Clémentine [00:25:08]: He does. I actually found out about the guy on Reddit because he does extremely long threads about the different models he evaluates and the kind of questions that they get right or wrong. He does his evaluations in German, if I remember properly. So it's usually very interesting to see how he does it. He's super rigorous, but he does, I don't know, 15 prompts. So a rigorous vibe check.
Swyx [00:25:35]: So I've read those things on the local LLM subreddit and it's a little bit excessive. I don't know if I need all that, but I'm glad somebody does it. To me, he's my automated vibe eval. I don't know who he is, but he shows up, so that's about it. So we wanted to cover specific choices around the new leaderboard. So congrats on launching it. You corrected a bunch of very fundamental data science things, like the variance between the benchmarks, as well as selecting for better benchmarks. I think obviously MMLU Pro is the top one, just because that's the top number that a lot of people report. The headline figures are, for example, it's 10 choices instead of four, and it's actually reviewed by experts instead of just not reviewed by experts. Any other sort of special notes that you would, basically, I want to do a quick tour around the ones that you picked, right? MMLU Pro, GPQA, I think these two are very well regarded. I have Eval as well. I noticed that Apple Intelligence is the only benchmark that Apple Intelligence used. Everything else was their own internal evals, but Apple Intelligence picked IFEval as their benchmark. Anyway, so do you want to comment quickly on some of the ones that you picked? Yeah.
Clémentine [00:26:50]: So for IFEval, I think it's a very interesting one because it's like unit tests, but for language, right? When you evaluate coding LLMs, you give them a bunch of unit tests, and you see if the functions that the LLM has written is able to make all the unit tests work. And IFEval behaves in literally the same way. They are giving prompts with very strict instruction formatting, and they are only evaluating instruction following. And I find it very interesting because it's not a metric which is ambiguous at any step. A lot of evaluations which are looking at the content are going to be using bag of words or embeddings to try to get like semantic similarity. Here you don't care. You are literally evaluating on understanding instructions. And I think it's a very smart data set. I loved it. We also added GPQA, which I've wanted to add to the leaderboard since it came out. Basically MMLU, but PhD level. Super complex questions which have been written by PhD experts and which are easy kind of to answer. If you have a PhD in the field, but not if you don't. So I think those ones are super interesting. They are only in science.
Alessio [00:28:12]: Yeah, I wanted to know if there's a black market for like the actual data sets that go in the benchmark. I know you have a gating mechanism to get the actual questions to make sure that models don't get contaminated. Do you ever get people reaching out to you? They want to buy the question answers to get better scores on the model. I wonder if marketing budgets are being spent on that.
Clémentine [00:28:34]: So for GPQA specifically, anyone can have access to the answers. You just need to create an account and say yes to the gating system and you will have access. The gating system is mostly here for bots, basically to prevent bots passing the web from getting access. However, for the Gaia benchmark, which I was part of, which is a benchmark for agents, we actually got contacted by some institutions from some specific countries who were actually like, well, can you give us the answers to the test sets? We're going to keep it for our Intel benchmarks. And we were like, no, have you heard of what a test set is? But we actually got contacted and they were like, yeah, we think it would really help our safety for our use cases. It's funny.
Alessio [00:29:25]: Yeah. Well, I asked thinking that you would say no, nobody would ever ask that, but humans are humans. Also, I know you work closely with Haley Sholkoff from Flutter AI on this, so I DMed her. Last night I asked her some questions I should ask you. So thank you, Haley, for your help. She told me to ask you about MMLU prompt format choices and whether or not there's a right choice when building prompts for the benchmarks. And this is kind of like the GPQA example, you know, maybe you two are experts, so you're kind of having these discussions. For me, it's like, I don't even know what all the options are. So I would love for you to maybe break that down too, you know, there's the benchmark, which is like the questions and the answers and like how you evaluate them. But then there's also how do you prompt the model to actually ask them? So any insights you have, I'm sure would be fun to share.
Clémentine [00:30:21]: Okay, so for MMLU specifically, it's a multi-choice evaluation. So you have a prompt and you've got many ways to prompt a model. MMLU that we chose is the one which was used in the harness. So it's question, column, the actual content of the question, return to the line, choices, column, go to the next line, A dot first choice, B dot second choice, and then we return to the line, answer, column. And we did a bunch of experiments at some point by trying different methods, just removing question, removing choices, removing answer. And we got a variation of 30 points on 100, depending on the prompt choices, and 30 points is insane in terms of the variation of evaluations. So the smallest prompt we have was just asking the question, and then we look at the log probabilities of all the choices. So we select the good choice as the one with the best log probability. The more complex one that we had was questions, the question, choices, and enumeration of the choices, but prefixed with letters between parentheses and not letter and then a dot. And this one got the best scores across most models. And in terms of contents, both source prompts have the same, because if you look at the log probabilities, if the model actually has the knowledge, the best log probability should be the best choice, and giving it explicitly the choice should not change anything in terms of contents you're looking at. But yeah, we got 30 points of difference on this. And we actually partnered with Outlines to do a blog post about it on how structured generation can improve evaluations by a lot. And in terms of MMLU, you can also evaluate it in another way, which is what Helm does. And in this case, you do not look at the log probabilities of the choices, you actually ask the model to generate a letter. And you take the generated letter, even if it's not in the option spaces, let's say. So if you say I've got choices A, B, C, D, and the model answers cat, well, cat is wrong. And so, shame for the model, it is wrong. We chose to run multi-choice evaluations in a log-likelihood way because it's way less expensive than running evaluations in a generative way for most tasks. And it's also kind of easy to parallelize, usually, because if you're only looking at one token of generation, then you can batch it very easily.
Alessio [00:33:30]: Are the multiple choice benchmarks much easier for the models? Do you have any intuition on how would you stack rank? Because you have the MMLU, then you add GPUA, then you have the math benchmark, you have BBH. Then you run multi-choice, then there's open generation without formatting, then there's formatting-driven ones like IFEval. Which ones are hardest, most impressive? Which ones are easiest? And how did you pick this exact mix?
Clémentine [00:34:01]: The two hardest evaluations on our benchmark are math because we only selected the hardest questions. We selected the level five questions. This is a choice that we made because we wanted an evaluation which was discriminative to allow us to see which models were actually good or not. And also because it's very costly to run the full data set. We realized that it would take several hours for a 7b just for this specific data set. And we were like, no, we've got to cut stuff. What do we do? And so one of the reasons behind us using so many multi-choice evaluations is the fact that we are compute constrained. We are using nodes with H100 on them. So every evaluation we'd run on one node with 80 gigs of RAM. And if you look at, for example, Vantage, which shares prices of those kinds of instances, in terms of public price, we are at about $100 an hour. So if we evaluate a 7b model at the moment, it takes approximately two hours. If we evaluate a 70b at the moment, it takes around 20 hours. So there's a limit to how much compute and how much money we can spend on this, right? And this is also a reminder, which is important for the community, because sometimes we get some messages like, I submitted a 70b model yesterday, why was it not evaluated? And I'm like, first of all, do you think compute grows on trees? If you have an NVIDIA GPU tree, give it to me, right? I want more GPUs. And also, it takes a lot of time to evaluate models. And yeah, to go back to your initial question about the benchmarks, the two hardest are so math, and yes, it's a generative evaluation, and generative evaluations in general are harder than multi-choice, but they are also harder to get right because of the metrics. I can go back to this afterwards. And the second hardest evaluation we have is MUSR, multi-step soft reasoning. And it's hard because it's super long context. Basically, it's murder mysteries, and then the model needs to find who is the culprit. The murder mysteries are like rule-based generated, and few models do better than random on this one at the moment.
Alessio [00:36:28]: Yeah, great. Great to see benchmarks that models don't do well on. If you just look at the results, it's like, these models are amazing. And then you use them, and you can clearly see there's a lot of room for improvement. So that's great. How do you kind of take this, in a way, responsibility, right? For whether you want it or not, this is one of the lighthouse things that people look at when evaluating models, like your leaderboard. What are maybe some of the hard decisions that you have to make internally? Because you kind of have to balance how you can face the company, but also the scientific objectivity of these things. What are discussions that you had internally on how to pick this, and balancing the commercial side versus the more research side? And yeah, whether or not you had people reach out to you and say, hey, you got this completely wrong. This is actually what the leaderboard should look like. How do you deal with those disagreements from the community?
Clémentine [00:37:26]: We know that we have, as you mentioned, a huge responsibility towards the community, because this is a place where people can evaluate their models, and they can also compare and cut through all the marketing bullshit, right? If you release tomorrow a model, and you're like, my model is the best model ever, we will actually evaluate it, and we will give you a number. We need to be very fair about our evaluations. This means that for the choice of evaluation, we discussed a lot internally with different people, so Louis, Tensel, Tom Wolfe, Nathan, and I, basically, and so we made short lists of which evaluations are relevant at the moment, both in terms of their contents, in terms of their stability, how well they are seen in the community. And then we spent, I'd say, about a month just running the evaluations on a wide variety of models to make sure that the implementations were absolutely correct and fair for all models. For example, when we were evaluating the version 1 of the leaderboards, we observed that Drop was using a dot as an end of sentence token, and so a lot of floating point answers would be cut off, and so would be incorrect. This was for the v1, and so we actually had scratched entirely this evaluation, because the implementation was incorrect. For v2, we spent much longer just looking at every nook and cranny, making sure the few short samples were fixed, making sure everything was properly formatted, that there were no backslash n running around or whatever. We also know that some models have issues with their tokenizers, so we made sure that they were still being evaluated properly on generative evaluations, because we know it's going to be used, and so numbers need to be as right as possible. And there isn't really a commercial aspect to the leaderboard, however, because basically we are just spending money on the thing, because we think it's a very useful resource for the community to have, but people are not paying for their evaluations to be there. It's a gift to the community, I guess.
Swyx [00:39:56]: I wonder about the compute, right? You have basically a standing H100 cluster, but the number of models grows every day. I think you cache them, you also remove models that are maybe contaminated. I think that this happens a lot, that some new model will suddenly show up at the top of the leaderboard, and then people will discuss, and they're like, oh yeah, it's contaminated, and you have to withdraw them. I just wonder about the economics of this thing. How much are you spending? You just have one standing cluster, and you just have a queue. Is that as simple as that?
Clémentine [00:40:35]: It's actually more complex. HuggingFace has one research cluster, and so the research cluster is used for every research experiment we have. If the FindWeb team is creating a new super cool dataset for you to train your model on, it's going to be on the cluster. If the IDFX team is creating a new multi-model model, it's going to train on the cluster. The OpenLLM leaderboard team is running on the spare cycles of that. We actually changed the way that our jobs are queued and launched. Basically, the leaderboard jobs are launched with the lowest priority of the cluster. Anything which is launched will kill our jobs if the cluster is too full. So that's why we can give it to the community, in a sense, because it's not costing us that much. It would be lost compute anyway. However, it means that sometimes the queue holds because the cluster is full, and users are not always super happy about it. But they get cool machine learning artifacts, so I think they should be happy.
Swyx [00:41:41]: Is there a way for the community to donate compute to you? Is there an interface that you can easily transfer your jobs to a different cluster?
Clémentine [00:41:51]: It's actually been discussed a lot, and we are thinking about adding the option to run evaluation on inference endpoint, where people would be able to pay for the compute of their evaluation. The thing is, at the moment, we really wanted to use a EleutherAI harness because it's a big stable library that everybody uses, and we think that Elusive is doing a great job at evaluations in general. But we have the functionality to run evaluations on inference endpoint in our own evaluation library, which is called Lightval. So we will have to port this functionality to the harness before being able to give it to the users. It's not been high on our priority list because then we will have to set up possibly another space where evaluation will run, or maybe people will have to duplicate some stuff. It's more engineering, and we've been a bit swamped with things to do.
Swyx [00:42:47]: I can imagine. Yeah, so hopefully when that opens up for inference endpoints, the only thing I'll caution is that all the inference providers write their own CUDA kernels and implementations of stuff. So sometimes you won't get one-for-one the same model, even though it's the same weights, but it's not exactly the same performance of the model because they quantize or do whatever they want to do with the shortcuts for attention.
Clémentine [00:43:17]: So regarding quantization, we usually indicate precisely what the precision of the model is. So you can find some models in several precisions. I guess this should be fixed by SART, but yeah, if evaluations run on different hardware with different batch sizes, results are going to be slightly different.
Swyx [00:43:38]: We're going to ask maybe three dimensions of benchmarks, and then we'll ask about missing benchmarks that you really want from the community. So the first one is something that the community is discussing a lot, which is long context. You already talked about Muser, but the other one that's popular is the very famous needle in a haystack. There are a lot of variations of needle in a haystack. We talked about this in a previous podcast with advanced needle in a needle stack and variable tracking and all that. Do you think there should be a long context version of the leaderboard, or how are you going to cut it such that you accommodate those things?
Clémentine [00:44:15]: For the leaderboard specifically, that's why we added Muser, because it's long context reasoning. In terms of high quality long context reasoning benchmarks, I can think of two which I really like. One is called a benchmark for learning to translate a new language from one grammar book, and it's actually a very fun data set where they basically provide the LLM with a grammar book written by a linguist on a small language, which is super low resource called Kalamang. Since it's so low resource, you're sure that there is no data about it anywhere on the web. Then they ask questions about the grammar, what would be the correct form, etc. This is reasoning, this is language skills, this is super long context because it's a book. I think this data set is very interesting in terms of long context. There was also LNAI, which made a benchmark which they called a novel challenge for long context model, where basically they took full-on novels published last year. They asked people who had read it to do summaries and to do adversarial descriptions of events happening in the book, which require you to have understood the full book to answer. They prompted models with that, so also a very long context evaluation because you've got a full book and then you've got those questions that you need to answer correctly and also not contaminated because hopefully the books are not in training data yet. Yeah, it's new novels. Yeah, definitely. So I think those kind of data sets are more interesting. Yeah, go ahead.
Swyx [00:46:03]: You just gave me an idea that Goodreads should be a data set because these are all novels that are commentaries about the contents of the novel.
Clémentine [00:46:12]: Definitely. There is definitely something to do about this.
Swyx [00:46:18]: Okay, that's long context. Sorry, go ahead, Alessio.
Alessio [00:46:21]: You mentioned the GAIA benchmark before that you worked on. What about agents, all of that part? Do you think we have good agent benchmarks? Do you think agent benchmarks are worth it? Yeah, curious for your thoughts.
Clémentine [00:46:34]: So for agent benchmarks, I haven't followed the literature so closely for this year, but when we did the GAIA benchmark, the main problem that we observed was that almost all agentic benchmarks would take LLMs, put them in a black box environment, which was absolutely not the real world, and then ask them to do things using very specific APIs. And that's kind of what started the GAIA project, actually, because we had this mental model of what agents could do, especially like AI assistants. We had this list of tasks of we expect them to be able to browse the web, we expect them to be able to extract information from structured places, from having access to modality, tools, etc. And from this, we built the GAIA benchmark. So really not from a capability standpoint, but more through, I'm going to call it proxy tasks, right? We expect agents to be able to do stuff and stuff. So reasoning on so many items, using so many tools. And that's how we built it. Instead of creating those boxed environments, which do not generalize well to the real world, GAIA basically tests your model on the real world. So I hope we get more datasets like GAIA. We basically provided the full recipe, and I really think that anyone could contribute or create similar datasets. So that would be one of the directions I would be excited about to see GAIA 2, GAIA 3, people thinking about creating tools also. Depending on which tools are created, some tasks are going to become way easier. So how do you add complexity to that, etc?
Swyx [00:48:28]: I interviewed Thomas Scialom at the ICLR poster session on GAIA, and for people who want to know more about GAIA, they can refer to our ICLR episode. The other big agent benchmark of this year has been SweetBench, much more coding oriented. I'm just curious if you have any thoughts or if you've looked at SweetBench at all.
Clémentine [00:48:49]: I remember going to the poster actually, but no, out of the blue, I wouldn't be able to give you feedback on it right now.
Swyx [00:48:55]: Just poking. Okay, then we have a question about ARC.
Alessio [00:49:00]: Yeah, just curious to get your thoughts. You know, obviously the ARC challenge got a new million dollar boost to get it solved a couple of weeks ago, so a lot of eyes on it. I think maybe some people are saying...
Clémentine [00:49:14]: Because we've got two ARC challenges. Like we've got challenge, which is a subset of the LNAI ARC dataset, and then you've got the Cholet ARC AGI challenge. Which one are you talking about?
Alessio [00:49:25]: Yes, the AGI challenge. Well, first of all, I'm curious if you think that actually is AGI, if you solve it, and just overall thoughts on the more challenge-driven things rather than evaluation, benchmarks driven.
Clémentine [00:49:41]: I don't think if you solve it, it's AGI. I think that focusing at the moment on trying to reach AGI is also a very bad objective, to be fair. But I'm very excited about this specific dataset. I'm looking forward to see what happens because I took a stab at some questions and basically they are great. They are pure logic. One of the things that we are missing at the moment in terms of LLM evaluations is complex logic, I think. Models are very bad at this. If they manage to learn the patterns and generalize on something which is logic-based, then we will have reached a step in reasoning, which will be very interesting.
Alessio [00:50:26]: Just overall, more meta question. How do you figure out whether or not a benchmark is actually useful? Everybody wants to build benchmarks, kind of like test sets and things like that. Do you have any quick ways, kind of like you have a vibe check for model? Do you have a vibe check for benchmarks?
Clémentine [00:50:43]: Actually, I do, but... Okay, so first thing is, and like the low investment version is, you first look at the paper and you want to see who made the dataset. And by this, I mean, was it model generated? Was it human generated? Were the annotators paid properly? Are they actually native English speakers if your dataset is in English? Etc. You want to know what is the quality of the dataset from the metadata, basically. And then you want to know what were the assumptions behind the dataset. What do they think their dataset is a proxy for? And does that sound logical? And then you want to look at the questions. You want to actually go through the dataset. You want to look at the prompts. Are you able to solve them? Do you see obvious mistakes? Are the prompts cohesive in terms of format? Like, is the formatting consistent? And you want to ideally take a small look at the codes. And if you have more time to invest on this, you can basically just use it for yourself on a bunch of models that you know are good. You want to use it on a small good model, like maybe, I think, 5.3. Like, it's very debated, but it's not that bad for its size. You've got a bunch of around 2 billion parameter models, which are good enough for this. So it wouldn't be too expensive. And then you want to test it on a very big model. That everybody knows is good. Like, when to or command R plus, for example. And if it's a generative model, you look at the generations. Are they, like, well made? Are they truncated? Do they look realistic? And then it gives you more of an idea of the quality. Because the quality of a lot of benchmarks will rely on the quality of their metrics. And if you are using, for example, an exact match metric, you want to make sure that you can actually extract something from the answer. GSM 8K is very good at this, because the output format is very constrained. But some evaluations are very bad at this. Drop, for example, is using a combination of bag of words to estimate whether the correct answer was given. And this is not a good metric, for example.
Swyx [00:52:58]: There's an old school NLP thing to use bag of words. Yes. It's kind of like a blue score. Okay, just in case you have one. Is there something that you wish somebody built a benchmark for that you really wanted to include, but you couldn't find it?
Clémentine [00:53:16]: Yes. I think that there are a bunch of things that we would need. But one thing is model calibration. Nobody's evaluating model calibration at the moment. And I think it's a problem. Model calibration is...
Swyx [00:53:29]: What is model calibration?
Clémentine [00:53:32]: You have a very confused face. This is very fun. Basically, a model is said to be well calibrated if the log probability score of an answer correlates well with how correct the answer is. So you want a model which... You can basically see it as the self-confidence of the model, right? So you want a model which tells you, yes, this is true, to have high probabilities of this, if it is actually true. And this thing specifically is called calibration. And it's not that hard to measure. You could use any multi-choice evaluation set to test this. I think there are more interesting datasets to build to test that. But if we have well calibrated models, it will open the door to basically being able to have models with confidence intervals about their answers. And you would be able to say, the model is highly confident about what it's saying. Or the model is in doubt, and you could give small confidence scores. I think this would be very interesting.
Swyx [00:54:42]: Yeah, there's some papers at ICLR on uncertainty as well. The quick response I'll give to that is, I think it's well known that base models are better calibrated than instruct-tuned models, right? So just the instruct-tuning just screws it up, makes it overconfident, makes it too much like a human.
Clémentine [00:55:00]: Therefore, it's... Yeah, it's tricky.
Swyx [00:55:02]: But yeah, I agree with this thing. We should have a benchmark for it and it'll get better.
Clémentine [00:55:07]: Yeah, I hope so. And I guess a bunch of other things would be interesting to evaluate. I think that robustness to prompting, nobody does it because it's too expensive. But if I prompt a model with 10 variations of the exact same prompt in terms of content, I don't want to get 10 different answers, right? And it's kind of linked to calibration. It's something that should be taken for granted in LLMs, but it's actually not working that well. And if I had to take a third choice, because I'm very greedy, you asked me for one, but you're getting three. I would love to see more things about psychofancy and basically all the ways into which models can be problematic in their interactions and put people in basically thought bubbles. You don't want people to be on social network too when they talk to a chat model, right? You want the chat model to be assertively saying what is factually true or not. Some things are factually true, right? The earth is round, gravity exists. A lot of things should not be debated and models should be assertively telling users that they are wrong if they are saying that those do not exist. Awesome.
Alessio [00:56:27]: This was a great kind of run through the leaderboard and a lot of the questions we already took a lot of your time. Before we wrap, maybe just one last thing. Any predictions for like leaderboard v3? Like if you go one year from now, do you think most models will have kind of top this new v2 too? Or how long do you think it's going to last before you need a new one?
Clémentine [00:56:48]: I'm actually working on the next version.
Clémentine [00:56:53]: I'm actually working on the next version, which now I'm not going to talk too much about it. But I think that we still have a lot of range for reasoning and mass evaluations at the moment. I think that we still have a lot of the evaluation space to explore. Long context, we're just getting started. I assume that some things like instruction, for like EF eval, for example, I assume that models are going to become very good at it very soon. And sadly, probably GPQA, because I think that it's going to be contaminated at some point. But yeah, basically the next version of the leaderboard would be depending on how fast models changed. It would be a similar version with reasoning, mass, maybe code if we can add it, because now all models should be able to code a bit. And I would really like to add a psychofancy evaluation for the next version. Yeah, well, but it's in the far future. So that's the end of my predictions.
Alessio [00:57:58]: Awesome. Yeah, thanks so much for coming on. We're going to link all of your previous work in the show notes so that people can read through it. And people can follow you on Twitter or X to stay up to date. Sorry, Yvonne, don't unfollow us.
Swyx [00:58:10]: Follow her on Hugging Face. Hugging Face is a social network.
Clémentine [00:58:13]: Yeah, that's true.
Alessio [00:58:16]: Yeah, that's it really. Thank you so much.
79 episodes



