Love stories from listeners of Barangay LSFM are featured in this weekly radio program. Listen in as Papa Dudut reads the letter of a "kabarangay" who shares his/her heartfelt experience. A dramatization brings the audience closer to feeling the joy, the pain, the ups and downs of being in love--something that each one of us can relate to.
…
continue reading
Content provided by Peter Rukavina. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by Peter Rukavina or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://player.fm/legal.
Similar to Peter Rukavina's Podcast
The Women's Podcast, hosted by Róisín Ingle & Kathy Sheridan. Producers: Róisín Ingle and Suzanne Brennan. By women, for everyone. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
Join University of Washington professor Jeff Shulman for a seventh season exploring the far-reaching impacts of Seattle's physical and cultural transformation. Notable guests from earlier seasons of Seattle Growth Podcast include Hall of Famer Lenny Wilkens, 3-time NBA All-Star Detlef Schrempf, NBA champion Wally Walker, Sonics legend Slick Watts, Pete Nordstrom, Craig Kinzer, Port Commissioner John Creighton, Paul Lawrence, City Councilmember Tim Burgess, SDOT director Scott Kubly, Tim Burg ...
…
continue reading
Live magazine programme on the worlds of arts, literature, film, media and music
…
continue reading
Nightlife with Phil Clark and Suzanne Hill has everything you need to get you through the night, seven nights a week.
…
continue reading
Feed your mind. Be provoked. One big idea at a time. Your brain will love you for it. Grab your front row seat to the best live forums and festivals with Natasha Mitchell.
…
continue reading
Bullseye is a celebration of the best of arts and culture in public radio form. Host Jesse Thorn sifts the wheat from the chaff to bring you in-depth interviews with the most revered and revolutionary minds in our culture. Bullseye has been featured in Time, The New York Times, GQ and McSweeney's, which called it "the kind of show people listen to in a more perfect world."
…
continue reading
A peripatetic podcast in which Leigh Sales and Annabel Crabb discuss what they're reading, watching, cooking, listening to or irrationally exhilarated by.
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!

))
Building the City Cinema Alexa Skill
Manage episode 173638137 series 1322274
Content provided by Peter Rukavina. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by Peter Rukavina or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://player.fm/legal.
I had my first Alexa Skill certified today, one I built over the past couple of weeks for City Cinema here in Charlottetown.
“Alexa Skills” are custom apps built for Amazon’s voice-controlled Echo line of products; think of them as a very early prototype of the computer on Star Trek, but lacking most of the artificial intelligence.
While Echo devices aren’t yet available for sale in Canada, they work in Canada, at least mostly, and it’s clear they’ll be here eventually. So it’s a good time to build up some “voice app” muscle memory, and City Cinema was a good, simple, practical use case.
Simple and practical because there’s really only one thing people want to know about City Cinema: what’s playing. Tonight. On Friday. Next Thursday.
So here’s a high-level overview of what it took to make an Alexa Skill.
First, I needed to select an Invocation Name. This is the “trigger word” or the “app name” that Alexa will glue to my skill. I selected the obvious: City Cinema.
Next, I created an Intent Schema, a JSON description of the things my skill can do, its methods, in other words.
In this case, it can only do a single thing–tell you what’s playing–so there’s only a single intent defined, WhatsPlaying, that has an optional parameter (called a “slot” in Alexa-speak), the date. There are also a few built-in intents added to the schema to allow me to define what happens when a user answers “yes” or “no” to a question, and when they cancel or stop.
{ "intents": [ { "intent": "WhatsPlaying", "slots": [ { "name": "Date", "type": "AMAZON.DATE" } ] }, { "intent": "AMAZON.YesIntent" }, { "intent": "AMAZON.NoIntent" }, { "intent": "AMAZON.CancelIntent" }, { "intent": "AMAZON.StopIntent" } ] }
Next, I defined the Sample Utterances, a list of the actual things that users can say that will initiate a “what’s playing” lookup:
WhatsPlaying what's playing on {Date} WhatsPlaying what's playing {Date} WhatsPlaying what's on {Date} WhatsPlaying what's showing on {Date} WhatsPlaying what is playing on {Date} WhatsPlaying what is playing {Date} WhatsPlaying what is on {Date} WhatsPlaying what is showing on {Date} WhatsPlaying showtimes for {Date} WhatsPlaying what are the showtimes for {Date} WhatsPlaying what are showtimes for {Date} WhatsPlaying showtimes for {Date} WhatsPlaying the schedule for {Date} WhatsPlaying schedule for {Date}
Defining these utterances is where you realize that a lot of what we call “artificial intelligence” is still very ELIZA-like: a nest of if-then statements.
Finally, I pointed the skill at an API endpoint on a server that I control. There are no limitations here other than that the endpoint must be served via HTTPS.
From this point, I could code the endpoint in whatever language I liked; all I needed to do is accept inputs from Alexa, and respond with outputs.
I opted to code in PHP, and to use the nascent third-party Amazon Alexa PHP Library as a convenience wrapper.
There are a bunch of things the endpoint must do that using this wrapper makes easier: requests must be validated as having come from Amazon, and there must be application logic in place to respond to LaunchRequest, SessionEndedRequest, and IntentRequest requests.
Other than that, the heavy lifting of the skill is relatively simple, at least in this case.
When a user says, for example, “Alexa, ask City Cinema what’s playing tonight,” Alexa matches the utterance to one of those that I defined, WhatsPlaying what’s playing {Date}, and passes my endpoint the intent (WhatsPlaying) and the date (as YYYY-MM-DD).
So I end up with a PHP object that looks, in part, like this:
[intent] => Array ( [name] => WhatsPlaying [slots] => Array ( [Date] => Array ( [name] => Date [value] => 2017-03-02 ) ) )
From there I just use the same business logic that the regular CityCinema.net site uses to query the schedule database; I then munge the answer into SSML (Speech Synthesis Markup Language) to form the response. I pass back to Alexa a JSON response that looks like this:
{ "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": "Playing at City Cinema on ????0302: Jackie at 7:00.
Do you want to hear a description of this film?
" }, "card": { "content": "Jackie at 7:00", "title": "Playing Thursday, March 2", "type": "Simple" }, "shouldEndSession": false }, "sessionAttributes": { "Operation": "FilmDetails", "Date": "2017-03-02" } }
While I can return a plain text reply, using SSML allows me to express some additional nuance in how dates and times are interpreted, and to insert breathy pauses when it helps to increase clarity.
Note that I also pass back some sessionAttributes values, Operation and Date. This allows me to respond properly when the user says “yes” or “no” in reaction to the question “Do you want to hear a description of this film?”; they are, in essence, parameters that are passed back to my endpoint with the follow-on intent. Like this, in part:
case 'AMAZON.NoIntent': if (array_key_exists('Operation', $alexaRequest->session->attributes)) { $operation = $alexaRequest->session->attributes['Operation']; } switch ($operation) { case "FilmDetails": $message = ""; $message .= "Ok, see you at the movies!"; $message .= ""; $card = ''; $endSession = TRUE; break; } break;
The Alexa Skills API also provides facility for passing back a “card,” which is a text representation (or variation) of the speech returned.
For example, for a “what’s playing” intent, I return the name of the film and the time; if the user answers “yes” to the “Do you want to hear a description of this film?” question, then I follow up with a card that includes the full film description (I experimented with passing this back for speaking, but it was too long to be useful).
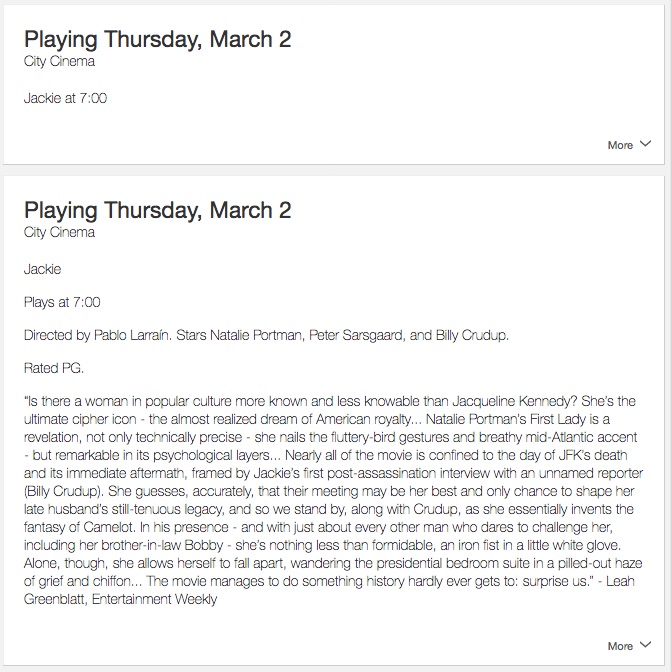
And that’s it. The application logic is a little more complex than I’ve outlined, mostly to handle the edge cases and the required responses to things like a request without a date, or a request like “Alexa, launch City Cinema.” But the PHP endpoint code only runs 257 lines long. It is not rocket science.
There’s an Apple-like certification process that happens once you’re ready to launch a skill to the public; in my case I submitted the skill for certification at 11:00 a.m. on February 28 and got back a positive response on March 2 at 1:46 a.m., so it was a less-than-48-hour turnaround.
The skill is now live on Amazon.com.
I foolishly selected “Canada” as the sole country where it would be available when I submitted the skill for certification; because the Echo isn’t available in Canada, this renders the skill effectively unusable for the moment because to use an Echo in Canada you have to pretend to be in the U.S.
I’ve opened this up to all countries now, which requires a re-certification. So in a few days the world should have access to the skill. And, eventually, when the Echo gets released in Canada, the skill should be of practical utility to Echo owners in the neighbourhood.
148 episodes
Manage episode 173638137 series 1322274
Content provided by Peter Rukavina. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by Peter Rukavina or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://player.fm/legal.
I had my first Alexa Skill certified today, one I built over the past couple of weeks for City Cinema here in Charlottetown.
“Alexa Skills” are custom apps built for Amazon’s voice-controlled Echo line of products; think of them as a very early prototype of the computer on Star Trek, but lacking most of the artificial intelligence.
While Echo devices aren’t yet available for sale in Canada, they work in Canada, at least mostly, and it’s clear they’ll be here eventually. So it’s a good time to build up some “voice app” muscle memory, and City Cinema was a good, simple, practical use case.
Simple and practical because there’s really only one thing people want to know about City Cinema: what’s playing. Tonight. On Friday. Next Thursday.
So here’s a high-level overview of what it took to make an Alexa Skill.
First, I needed to select an Invocation Name. This is the “trigger word” or the “app name” that Alexa will glue to my skill. I selected the obvious: City Cinema.
Next, I created an Intent Schema, a JSON description of the things my skill can do, its methods, in other words.
In this case, it can only do a single thing–tell you what’s playing–so there’s only a single intent defined, WhatsPlaying, that has an optional parameter (called a “slot” in Alexa-speak), the date. There are also a few built-in intents added to the schema to allow me to define what happens when a user answers “yes” or “no” to a question, and when they cancel or stop.
{ "intents": [ { "intent": "WhatsPlaying", "slots": [ { "name": "Date", "type": "AMAZON.DATE" } ] }, { "intent": "AMAZON.YesIntent" }, { "intent": "AMAZON.NoIntent" }, { "intent": "AMAZON.CancelIntent" }, { "intent": "AMAZON.StopIntent" } ] }
Next, I defined the Sample Utterances, a list of the actual things that users can say that will initiate a “what’s playing” lookup:
WhatsPlaying what's playing on {Date} WhatsPlaying what's playing {Date} WhatsPlaying what's on {Date} WhatsPlaying what's showing on {Date} WhatsPlaying what is playing on {Date} WhatsPlaying what is playing {Date} WhatsPlaying what is on {Date} WhatsPlaying what is showing on {Date} WhatsPlaying showtimes for {Date} WhatsPlaying what are the showtimes for {Date} WhatsPlaying what are showtimes for {Date} WhatsPlaying showtimes for {Date} WhatsPlaying the schedule for {Date} WhatsPlaying schedule for {Date}
Defining these utterances is where you realize that a lot of what we call “artificial intelligence” is still very ELIZA-like: a nest of if-then statements.
Finally, I pointed the skill at an API endpoint on a server that I control. There are no limitations here other than that the endpoint must be served via HTTPS.
From this point, I could code the endpoint in whatever language I liked; all I needed to do is accept inputs from Alexa, and respond with outputs.
I opted to code in PHP, and to use the nascent third-party Amazon Alexa PHP Library as a convenience wrapper.
There are a bunch of things the endpoint must do that using this wrapper makes easier: requests must be validated as having come from Amazon, and there must be application logic in place to respond to LaunchRequest, SessionEndedRequest, and IntentRequest requests.
Other than that, the heavy lifting of the skill is relatively simple, at least in this case.
When a user says, for example, “Alexa, ask City Cinema what’s playing tonight,” Alexa matches the utterance to one of those that I defined, WhatsPlaying what’s playing {Date}, and passes my endpoint the intent (WhatsPlaying) and the date (as YYYY-MM-DD).
So I end up with a PHP object that looks, in part, like this:
[intent] => Array ( [name] => WhatsPlaying [slots] => Array ( [Date] => Array ( [name] => Date [value] => 2017-03-02 ) ) )
From there I just use the same business logic that the regular CityCinema.net site uses to query the schedule database; I then munge the answer into SSML (Speech Synthesis Markup Language) to form the response. I pass back to Alexa a JSON response that looks like this:
{ "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": "Playing at City Cinema on ????0302: Jackie at 7:00.
Do you want to hear a description of this film?
" }, "card": { "content": "Jackie at 7:00", "title": "Playing Thursday, March 2", "type": "Simple" }, "shouldEndSession": false }, "sessionAttributes": { "Operation": "FilmDetails", "Date": "2017-03-02" } }
While I can return a plain text reply, using SSML allows me to express some additional nuance in how dates and times are interpreted, and to insert breathy pauses when it helps to increase clarity.
Note that I also pass back some sessionAttributes values, Operation and Date. This allows me to respond properly when the user says “yes” or “no” in reaction to the question “Do you want to hear a description of this film?”; they are, in essence, parameters that are passed back to my endpoint with the follow-on intent. Like this, in part:
case 'AMAZON.NoIntent': if (array_key_exists('Operation', $alexaRequest->session->attributes)) { $operation = $alexaRequest->session->attributes['Operation']; } switch ($operation) { case "FilmDetails": $message = ""; $message .= "Ok, see you at the movies!"; $message .= ""; $card = ''; $endSession = TRUE; break; } break;
The Alexa Skills API also provides facility for passing back a “card,” which is a text representation (or variation) of the speech returned.
For example, for a “what’s playing” intent, I return the name of the film and the time; if the user answers “yes” to the “Do you want to hear a description of this film?” question, then I follow up with a card that includes the full film description (I experimented with passing this back for speaking, but it was too long to be useful).
And that’s it. The application logic is a little more complex than I’ve outlined, mostly to handle the edge cases and the required responses to things like a request without a date, or a request like “Alexa, launch City Cinema.” But the PHP endpoint code only runs 257 lines long. It is not rocket science.
There’s an Apple-like certification process that happens once you’re ready to launch a skill to the public; in my case I submitted the skill for certification at 11:00 a.m. on February 28 and got back a positive response on March 2 at 1:46 a.m., so it was a less-than-48-hour turnaround.
The skill is now live on Amazon.com.
I foolishly selected “Canada” as the sole country where it would be available when I submitted the skill for certification; because the Echo isn’t available in Canada, this renders the skill effectively unusable for the moment because to use an Echo in Canada you have to pretend to be in the U.S.
I’ve opened this up to all countries now, which requires a re-certification. So in a few days the world should have access to the skill. And, eventually, when the Echo gets released in Canada, the skill should be of practical utility to Echo owners in the neighbourhood.
148 episodes
모든 에피소드
×Welcome to Player FM!
Player FM is scanning the web for high-quality podcasts for you to enjoy right now. It's the best podcast app and works on Android, iPhone, and the web. Signup to sync subscriptions across devices.
Similar to Peter Rukavina's Podcast
Love stories from listeners of Barangay LSFM are featured in this weekly radio program. Listen in as Papa Dudut reads the letter of a "kabarangay" who shares his/her heartfelt experience. A dramatization brings the audience closer to feeling the joy, the pain, the ups and downs of being in love--something that each one of us can relate to.
…
continue reading
The Women's Podcast, hosted by Róisín Ingle & Kathy Sheridan. Producers: Róisín Ingle and Suzanne Brennan. By women, for everyone. Hosted on Acast. See acast.com/privacy for more information.
…
continue reading
Join University of Washington professor Jeff Shulman for a seventh season exploring the far-reaching impacts of Seattle's physical and cultural transformation. Notable guests from earlier seasons of Seattle Growth Podcast include Hall of Famer Lenny Wilkens, 3-time NBA All-Star Detlef Schrempf, NBA champion Wally Walker, Sonics legend Slick Watts, Pete Nordstrom, Craig Kinzer, Port Commissioner John Creighton, Paul Lawrence, City Councilmember Tim Burgess, SDOT director Scott Kubly, Tim Burg ...
…
continue reading
Live magazine programme on the worlds of arts, literature, film, media and music
…
continue reading
Nightlife with Phil Clark and Suzanne Hill has everything you need to get you through the night, seven nights a week.
…
continue reading
Feed your mind. Be provoked. One big idea at a time. Your brain will love you for it. Grab your front row seat to the best live forums and festivals with Natasha Mitchell.
…
continue reading
Bullseye is a celebration of the best of arts and culture in public radio form. Host Jesse Thorn sifts the wheat from the chaff to bring you in-depth interviews with the most revered and revolutionary minds in our culture. Bullseye has been featured in Time, The New York Times, GQ and McSweeney's, which called it "the kind of show people listen to in a more perfect world."
…
continue reading
A peripatetic podcast in which Leigh Sales and Annabel Crabb discuss what they're reading, watching, cooking, listening to or irrationally exhilarated by.
…
continue reading
Player FM - Podcast App
Go offline with the Player FM app!
Go offline with the Player FM app!



